
Blog Post: Final Project Jornal
Hello Everyone!
This post will be about demonstrating how to use my Selenium-Based Manga Monitor, as well as the building process!
If you would like to follow along, this code is fully available in my GitHub repository: https://github.com/NoraAda/PIC16B/tree/main/Final%20Project
Personal Insight into the project:
This final project was a unique experience for me, since, before this project, I always followed someone’s instructions for all of the programs. So, before this experience, I have never had creative control. Therefore, for my final project, I decided to choose something personal and fun to do. As a result, I decided to make a project about searching for new chapters of manga in the top 5 websites I use in my day-to-day life. Choosing to make a project about a silly topic like searching for new chapters in manga made me feel that finally, I have a connection between my academic and non-academic interests. Moreover, when I was able to develop my own idea from scratch and the program started to slowly work according to my own idea, it reassured me that I did grow and learn a lot in the past few years and now can independently work on projects using my creativity and available online resources. In addition, this connection motivated me to finish its first version for the class and hopefully will inspire me to further work on it during the upcoming Christmas break. I hope that in a few months I can make it into something bigger and can share it with my friends’ group so they can also benefit from it.
Technical component:
It is an example of a python script which can be called through a terminal. Also, it uses users input in the terminal and gives output in the terminal as well. The first input of the program takes the title of needed manga. The input is processed by using text processing by regular expression to prepare the input for the search algorithm. This means that we disregard all non letter characters and transform it into the form convenient for our search algorithm.
The second input, devids users into two categories: if the user says any word starts from any letter not equal to N then we interpret his answer as Yes, the next program asks for the third input such as number of characters read before. If the answer had N as a first letter then the program interprets it as No and does not ask for chapters and assume that 0 characters was read. Also, it is important to note that this program uses Selenium. Selenium is an open source umbrella project for a range of tools and libraries aimed at supporting browser automation. It provides a playback tool for authoring functional tests across most modern web browsers, without the need to learn a test scripting language (Selenium IDE). It also provides a test domain-specific language (Selenese) to write tests in a number of popular programming languages, including JavaScript (Node.js), C#, Groovy, Java, Perl, PHP, Python, Ruby and Scala. Selenium runs on Windows, Linux, and macOS. But since in this class we used scrapy for homework #2, my first idea was to use scrapy but due to the website’s protection called CloudFlare it did not work properly. Hence, I decided to use Selenium to avoid detection by CloudFlare.
So, in order for my program to work, the users needs to complite these import commands:
# all needed imports
from pyvirtualdisplay import Display
from selenium import webdriver
import selenium
import re
import time
Next, I have two choices: to use Selenium to see all its operations or to download the Xvfb package to hide the process and use virtual display.
# prepare webdriver
selenium_spider, virtual_display = start_or_reload_display(driver_name='Chrome', detach_display=False)
It is possible on Linux and Macrasoft but hard for IOS. Main objective of this program is working with is open program using selenium. Each website is treated and processed separately to collect needed information about the manga in question. The processing is dependent on the CSS structure of the website and the CSS elements. So, we go from the home page of the website to the manga information page (using the adopted page) to collect the needed information about characters’ updates.
# specify a group of resources with the same CSS elements
urls_batch_1 = ['https://1stkissmanga.io',
'https://zinmanga.com',
'https://coffeemanga.com',
'https://kunmanga.com']
for url in urls_batch_1:
# construct the direct link to manga to check it if it exists
direct_link_to_manga = f'{url}/manga/{user_input_1_adapted}'
# connect webdriver to the direct link
selenium_spider.get(direct_link_to_manga)
So, first the program is trying to use direct link to find needed manga on the website.
# get the list of elements from '.heading' CSS-selectors
list_of_heading_elements_found = selenium_spider.find_elements("css selector", '.heading')
# check if the first '.heading' CSS-selector found text is about specific 404 error
if len(list_of_heading_elements_found) > 0 and (
list_of_heading_elements_found[0].text != 'Oops! page not found.'):
# if not - process this page
If this method fails for the needed manga, then the program will use search to find it.
# construct the link with suitable mangas found on searching page of the resource
user_input_1_readapted = '+'.join(user_input_1.lower().split())
searching_url = url + f'/?s={user_input_1_readapted}&post_type=wp-manga'
# and connect webdriver to this link
selenium_spider.get(searching_url)
Furthermore, optionally in the program can use a CSS object with a header to identify cases when manga was not found on the website but it is not mandatory since the program will determine that check was failed for this object.
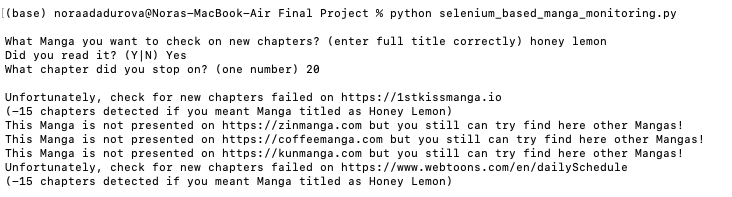
Also, in the text found on the informational page for manga, it is important to get the number of characters in the manga. This is important since we want to provide the user with the number of characters they still have left to read. This adds additional logic since we might get negative numbers. For example, because users made a mistake writing number of characters (for example 300 instead of 30), or the website is not as relevant for this manga so it is late on updates for this title, or if a program found the most relevant manga to the search but it is a wrong manga and has less characters. Hence, while building I accounted for this cases. In case, if it is a negative number of characters, “Unfortunately, check for new chapters failed on” and url for website used and a comment program says negotive number of chapters and comment “chapters detected if you meant Manga titled as” and name of needed manga.
If a manga information page is not found, the program uses search and selects the first option in the search assuming that it is the most relevant to the user’s demand. But if the program uses search and there are no matches then the program outputs “This Manga is not presented on” + name of the website and comment such as “but you still can try find here other Mangas!”
Code for calling needed function for direct link to manga website: (Also, note that full code of this function is publicly avalible at https://github.com/NoraAda/PIC16B/tree/main/Final%20Project)
# check the page on new chapters of the manga
get_processed_core_page(selenium_object=selenium_spider,
good_css_selector='li.wp-manga-chapter:nth-child(1) > a:nth-child(1)',
url_to_print=url,
chapters_already_read=user_input_2,
title_css_selector='.post-title',
good_css_selector_num=0,
title_css_selector_num=0,
bad_css_selector='.not-found-content')
Code for calling needed function for search option on the manga website:
# check the page on new chapters of the manga
get_processed_core_page(selenium_object=selenium_spider,
good_css_selector='span.font-meta:nth-child(2)',
url_to_print=url,
chapters_already_read=user_input_2,
title_css_selector='.post-title',
good_css_selector_num=0,
title_css_selector_num=0,
bad_css_selector='.not-found-content')
Also, for the website with similar structure, the problem uses CSS objects and correcting direct links. But in the second type (WEBTOON) of the website more text processing is needed since in order to find the correct link to the manga the program needs to know genera.
# resource with other CSS elements
webtoons_url = 'https://www.webtoons.com/en/dailySchedule'
# connect webdriver to webtoons_url
selenium_spider.get(webtoons_url)
# and get all of this public source code with selenium and some preprocessing
full_page_text_source = selenium_spider.page_source.replace('\n', '').replace('\t', '')
# try to find suitable links to the manga in full_page_text_source
list_of_useful_rows = re.findall(('(?:https://www.webtoons.com/en/)'
'(?:\w|-)+'
f'(?:/{user_input_1_adapted}/)'
'(?:list\?title_no=\d+)').lower(),
full_page_text_source.lower())
if len(list_of_useful_rows) == 0:
list_of_useful_rows = re.findall(('(?:https://www.webtoons.com/en/)'
'(?:\w|-)+/(?:\w|-)*'
f'(?:{user_input_1_adapted})'
'(?:\w|-)*(?:/)'
'(?:list\?title_no=\d+)').lower(),
full_page_text_source.lower())
if len(list_of_useful_rows) > 0:
# if at least one link to the manga found inside full_page_text_source
# take the first of them
webtoons_link_to_manga = list_of_useful_rows[0]
# and redirect webdriver to it
selenium_spider.get(webtoons_link_to_manga)
# check the page on new chapters of the manga
get_processed_core_page(selenium_object=selenium_spider,
good_css_selector='span:nth-child(6)',
url_to_print=webtoons_url,
chapters_already_read=user_input_2,
title_css_selector='h1.subj',
good_css_selector_num=1,
title_css_selector_num=0,
bad_css_selector='.error_area')
else:
print(f'This Manga is not presented on {webtoons_url} but you still can try find here other Mangas!')
So, if we want to add more resources, we need to create a transaction to either direct link or search and then we can use existing functionality of the program. Hence, this program can be expanded pretty easily and for an unlimited number of websites.
Multiple Test Cases:
Let’s check that the program workes correctly after downloading.
Please open the terminal and test these few different user inputs:
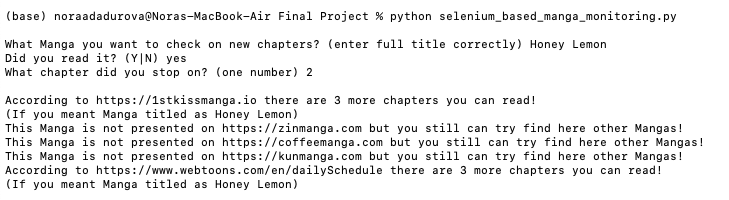
Test 1:
- Honey Lemon
- yes
- 2
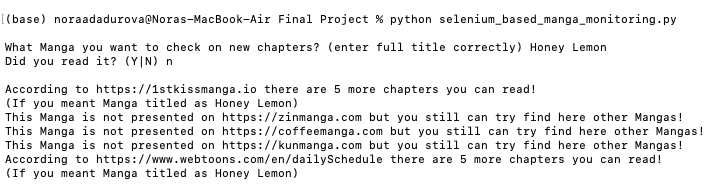
Test 2:
- Honey Lemon
- no
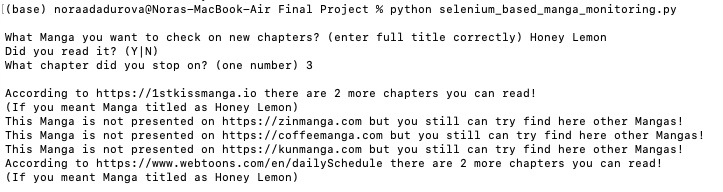
Test 3:
- Honey Lemon
- [just press enter button]
- 3
Test 4:
- honey lemon
- Yes
- 20
Test 5:
- the gamer
- yeh
- 300

Test 6:
- Nerd Boyfriend (meaning My Giant Nerd Boyfriend)
- Y
- 100
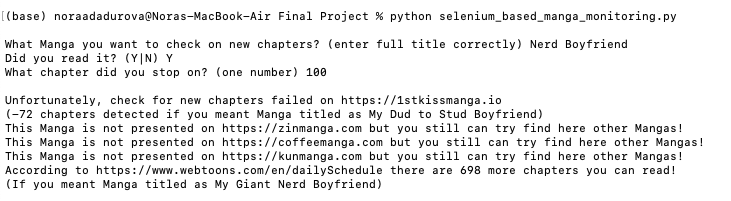
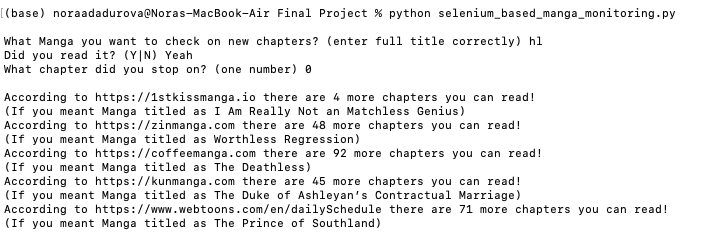
Test 7:
- hl (meaning Honey Lemon)
- Yeah
- 0
Conclusion:
To sum up, I enjoyed this first personal project because I can see myself using and improving it in the future due to my interest in manga. Moreover, being a practical person, I have struggled for a while with my classes at UCLA being too theoretical and not connecting to my non-academic interests or real life. Hence, this little project strengthen my confidence and interest in continuing to study since it demonstrated that this class and the past classes prepared me to work independently and gave me the necessary tools to make my ideas come true even if they are silly like helping to find chapter updates for a manga. Also, next, I hope to do a different project for a more serious real-life topic/issue with friends or by myself over the upcoming winter.